By Mark Cieliebak
Task Description
Sentiment Analysis is the task of detecting the tonality of a text. A typical setting aims to categorize a text as positive, negative, or neutral. For instance, the text “This is a nice day” is obviously positive, while “I don’t like this movie” is negative.
Some texts can contain both positive and negative statements at the same time. For instance, “I don’t like the color of this car, but the speed is great” would be classified as “mixed” sentiment. More fine-grained sentiment classification is possible by using a sentiment score, which can, for instance, range from -10 (very negative) to 0 (neutral) to +10 (very positive).
Sentiment is not Easy for Humans
The examples above are almost trivial to classify. However, in reality it is often not straightforward to determine the proper tonality of a text. Consider the statement “It is raining”. At first sight, many humans will consider this a negative statement – because they don’t like rain – but in some cases this might be a positive event (e.g. for a farmer who desperately awaits the water for her crop). In fact, if no further context is known, the tonality of this statement would be neutral.
It turns out that humans often disagree on the sentiment of a text: In an in-class experiment at ZHAW, we give our students 20 randomly selected tweets and ask them to annotate their tonality.
Before reading on, you might want to try is by yourself:
#Thailand Washington – US President Barack Obama vowed Wednesday as he visited storm-ravaged New Jersey shore to… http://t.co/Xzl4LFhs
@jacquelinemegan I’m sorry, I Heart Paris is no longer available at the Rockwell branch! You may call 8587000 to get a copy transferred!
Tim Tebow may be availible ! Wow Jerry, what the heck you waiting for! http://t.co/a7z9FBL4
Manchester United will try to return to winning ways when they face Arsenal in the Premier League at Old Trafford on Saturday.
SNC Halloween Pr. Pumped. Let’s work it for Sunday… Packers vs. … who knows or caresn. # SNC #cheerpracticeonhalloween
Going to a bulls game with Aaliyah & hope next Thursday
There is usually not a single tweet where all students of a class agree on the sentiment. Here are the annotation results for the samples:



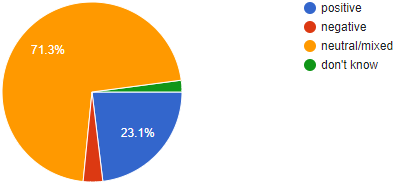
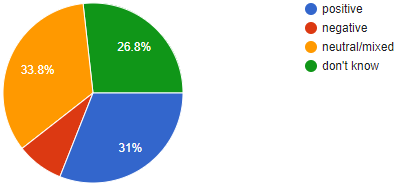
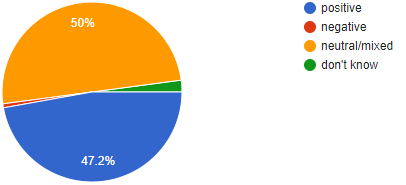
Scientific research has shown analogous results: In a huge experiment, researchers from Slovenia gathered a corpus of over 1.6 million tweets in 12 languages. Each text was annotated by one to three humans. The inter-annotator agreement – i.e. the ratio by which two annotators assign the same sentiment to a text – varies between 0.126 and 0.673 (note that the very low values might be due to low-quality work of some annotators).
Solving the Sentiment Analysis Problem
We will now take a closer look at the three-class-problem, which assigns one of the labels positive, negative or neutral to each text. This is probably the most commonly used settings for sentiment analysis. We assume for now that each class occurs equally often, i.e. that approximately 1/3 of all documents will be positive, negative, or neutral.
A classifier which assigns one of the three labels randomly to each text can be expected be correct for 1/3 of all cases (33%). This gives us a lower bound. On the other hand, we have seen above that even human labels are correct for at most 80% of all texts. We cannot expect an automatic system to do better than that. Thus, any reasonable classifier will have an accuracy between 33% and 80%.
It is obvious that occurrences of positive or negative words such as “good” or “hate” are strong indicators for the tonality of a text. Thus, a very simple solution for Sentiment Analysis is to count positive and negative words in the text. There exist extensive lists such as SentiWordNet which contain a tonality score for each single word. Using this approach can achieve an accuracy of up to 50%, which is not too bad for such a simple approach. But it is obvious that there is room for improvement.
At present, the most successful approach to Sentiment Analysis uses machine learning: The computer is given a large set of sample texts, and a label with the tonality for each text. This is the training set. The machine then “learns” which textual patterns are relevant for the tonality, and builds an internal model of these patterns. This model can then be used to predict the sentiment of new, previously unseen texts.
Until recently, NLP experts handcrafted the textual patterns (so-called features) that might be relevant to detect the sentiment. These included, of course, the occurrence of positive or negative words, but also negation, text length, number of words in upper-case letters, n-grams, number of adjectives or substantives (POS-tags), etc. Originally, these features were developed and implemented by hand, but in the last few years deep learning is used more and more often for sentiment analysis.
Our Contribution
We have implemented a sentiment analysis system that uses deep and distant learning on more than 90 million English tweets. This system won the SemEval competition in 2016 – an international competition with more than 50 participating teams from science and industry. Later, we trained the same system on Italian documents and won the EVALITA-2016 competition.
Deep Learning systems have one important advantage: they can generate relevant features from huge collections of text by themselves, without human input. Thus, they are language-independent and can be applied to any language, as long as sufficient texts are available.
Measuring the Quality of a Solution
A very straightforward quality measurement for sentiment analysis system appears to be accuracy: given a test set of, say, 3000 documents with human labels (the “gold standard”), run all the documents through the system and compare its output with the human labels. Count how many outputs were correct (i.e. human label and system output were the same tonality, e.g. positive). Assume that this is, for instance, 2700, then divide this by the total number of documents, 3000, to get an accuracy of 90%.
Accuracy is a very obvious measurement, and easy to compute. However, it has one major drawback: In some cases it is easy to obtain a very high accuracy even with a stupid system. Assume that the human labels for the 3000 documents from our test set are distributed as follows: 2800 neutral, 150 positive, and 50 negative. And now assume a trivial system that always outputs “neutral”, independent of the text. This system will be correct in 2800 test cases, thus, it will have an accuracy of 2800/3000 = 93%, although it does not do anything at all.
To circumvent this effect, researchers are often using the F1-score to measure the quality of a sentiment analysis system. This score takes into account the quality for each class separately, and then combines these sub-results to a final score by macro- or micro-averaging them. We refrain from giving the formal definition here (although it is not very complicated); if you are interested, please have a look here for a definition and an in-depth discussion.
For our purposes here, it is sufficient to know that the F1-score is between 0 and 1, where 1 would be an error-free system. In our example above, the F1-score of the naïve system that always outputs “neutral” would be 0.32 (macro-averaged over three classes).
Top Scores
How good is the best system for Sentiment Analysis? Unfortunately, there is no simple answer to this important question, since the performance of a sentiment analysis system heavily depends on which texts it is applied to.
To understand this, have a look at the following figure. It shows the results of the winning system of SemEval-2016 (actually, our system) when applied to different types of text (don’t worry about the F1-score, you can easily assume that this is the ratio of correctly classified documents for now).

As you can see, the system achieves an F1-Score of 0.73 on the DAI dataset (tweets), whereas it reaches only 0.46 on the JCR data, which is quotations from English Texts. There are many potential reason for these huge differences, and we will discuss them later on in more detail.
Our Contribution
We conducted a benchmark study to evaluate the quality of other state-of-the-art tools for Sentiment Analysis. We compared 9 commercial sentiment-APIs on seven public corpora (basically the same as above). The following chart shows the average Accuracy-scores of the systems for each corpus. REF: M. Cieliebak et al.: Potential and Limitations of Commercial Sentiment Detection Tools, ESSEM 2013.

Please note two important things: First, be aware that this study was conducted in 2013. The participating tools will probably have improved in the meantime, and will probably achieve much better scores nowadays. Second, none of the systems were trained on the corresponding corpora, whereas our system from the graphic above was explicitly trained and optimized on each of the corpora.
Nonetheless, the chart shows that the performance also varies drastically between different corpora.
Sentiment Corpora
In order to train and evaluate automatic sentiment tools, researchers and developers rely on sentiment corpora which contain texts that were manually labeled. There exists a vast variety of sentiment corpora, many of them for English, but also for many other languages.
Our Contribution
SpinningBytes has developed own corpora for German and Swiss German.
When using a corpus to train a machine learning system, three fundamental properties are important:
- Quality: Any machine learning system can only learn what is in the corpus. If the annotations in the corpus are erroneous or inconsistent, it is hard or even impossible to train an automatic sentiment analysis tool.
- Proper Domain: It is usually optimal to train a system exactly on those documents that it should be used on afterwards. This includes language, document type (review, tweet, Facebook post etc.) and content (for instance, reviews of laptops vs. reviews of snowboards).
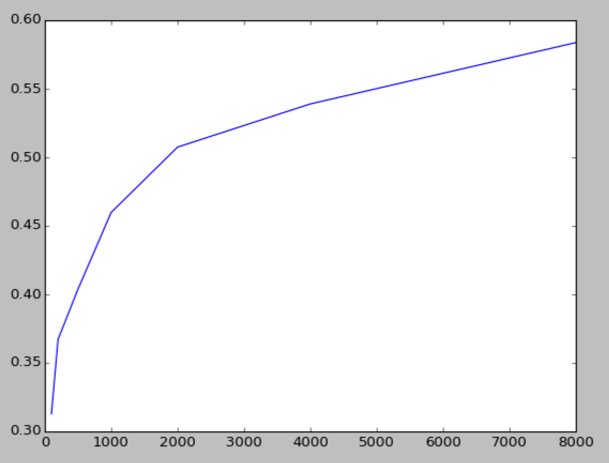
- Quantity: In general, the larger the corpus the better the system. The image below shows a typical learning curve of a sentiment system. The increase in quality is huge at the beginning, but later it approaches an upper limit, and more training documents only minimally increase the quality.
Do you need your Own Corpus?
In general, it is optimal if you train your system exactly on the data to which it should be applied. Thus, whenever possible, you should develop your own corpus and label the data.
Our Contribution
We wanted to know what is more important, proper domain or quantity. We trained and analyzed 81 sentiment systems on various domains, including reviews, tweets, and news headlines. There were two major findings:
- The best results were always achieved if a system was trained on the same domain that is was used for afterwards.
- Adding foreign-domain data to a domain-specific training set never improved the system. On the contrary, this reduced the F1-score by up to 14 percent points in some cases.
Developing your own corpus is not as difficult as it sounds: we have, for instance, manually labeled 10000 German tweets. Our annotators were computer science students, and each could label approximately 200 tweets per hour. Since every tweets was labeled by three annotators, we gathered 30000 labels, which took 30000/200 = 150 hours.
For a normal sentiment analysis system, you will typically start with, say, 1000-2000 documents, which will usually already give you a well-performing system. The learning curve will then show you if labeling additional documents is likely to give you any significant improvement.
Of course, there are several details to take into account: you have to gather the “right” texts; you have to write consistent annotation guidelines; and you need a proper tool for annotating, where you can track the inter- and self-annotator agreement of your annotators (to track the quality of your annotations). But all in all, it is often worth it to build your own corpus, instead of using existing corpora that do not match well with the intended text domain.
On the other hand, there are cases where you cannot develop a specific corpus for your target domain. This is especially the case if your target domain is not known at the time of training (e.g. for a generic social media monitoring tool), or if there are too many different target domains (e.g. if you want to analyze reviews of any potential product, from apples via hotels to cars). In this case, it is probably the best to collect as many labeled documents as possible, and use them for training your system. At least, this is what our experiments have shown.
Contribution
Emotions play an important part in our everyday interactions and are often more important than many people realize. They can give us an insight into aspects of human interactions that are otherwise closed to us and help us understand what motivates and engages people. Because of this, Sentiment Analysis has applications in many domains, like Brand Monitoring, Customer Care or Marketing, to name a few. Sentiment Analysis allows us to deal with this fuzzy, uncertain human issue in a structured, efficient, automated way. It helps businesses to be better informed and to make better decisions and we believe its possibilities are far from exhausted.