By Fernando Benites
schwiiz ja*
This year, the SpinningBytes team participated in the VarDial competition, where we achieved second place in the German Dialect Identification shared task. The task’s goal was to identify, which region the speaker of a given sentence is from, based on the dialect he or she speaks. Dialect identification is an important NLP task; for instance, it can be used for automatic processing in a speech-to-text context, where identifying dialects enables to load a specialized model. In this blog post, we do a step by step walkthrough how to create the model in Python, while comparing it to previous years’ approaches.
In the data, which was provided for this task, we are given a training set, consisting of around 17.5 k individual sentences which do not contain any context or additional information. Each sentence in the training data has a label belonging to four different cantons, which is a rough approximation for the dialect, especially since they are close to each other, spanning a region of 80 km times 80 km. The Swiss German sentence in the title of this article (* which means “swiss yes” in English) was taken from the corpus and is assigned to the Bernese dialect. The following are other interesting sentences: “ech was” (approximate English translation: “really something”, dialect of Lucerne); “im diskutiere han i immer gern rächt gha” (approximate English translation: “in discussions, I like to be right”, dialect from Zurich). Another concrete application motivating such a task, is to better differentiate between languages, especially problems such as identifying the language of a tweet, since it is often a colloquialism or transcription of spoken language. In the example of a popular program for language identification, a probably African-American tweet (clearly EN-US) was identified as Danish, which shows the importance of solving the task (For more information consult this paper).
The data from this year is basically the same as last year’s, with the difference that now we have a development data set which is the last year’s test data. We based our approach on the winning architecture from last year’s VarDial, but extended it in several way. The results from last year were as follows:
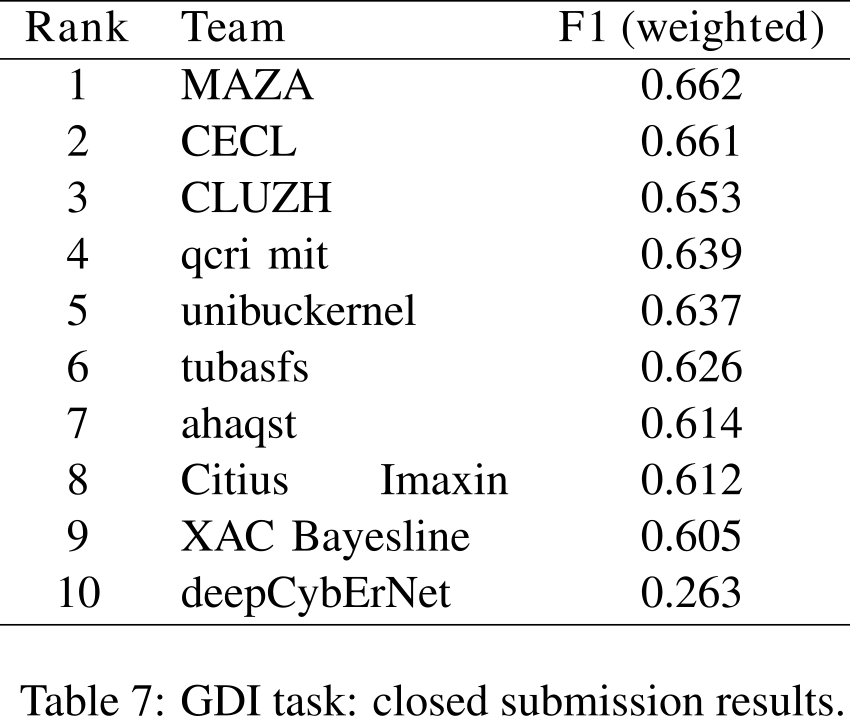
Below we show step by step how to increase the performance on this dataset, starting from scratch. Also, while building the system we compare the performance with the results above. The code is available here. One important thing to note: last year, weighted F-1 scores were used as evaluation measure, this year, it is macro F-1.
Hands On
You might now want to clone the git hub repository. You can run the baseline.ipynb (and “above”) in a jupyter python session. Below, we are going to reproduce the script.
We will first load the task data into the directory.
#based on https://github.com/ynop/audiomate/blob/master/audiomate/utils/download.py
import zipfile
import requests
from collections import Counter
def download_file(url, target_path=None):
"""
Download the file from the given `url` and store it at `target_path`.
"""
if target_path is None:
target_path = url.split("/")[-1]
r = requests.get(url, stream=True)
with open(target_path, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
return target_path
def extract_zip(zip_path, target_folder):
"""
Extract the content of the zip-file at `zip_path` into `target_folder`.
"""
with zipfile.ZipFile(zip_path) as archive:
archive.extractall(target_folder)
def get_data(fname=None, all=1):
#sstopwords=set(stopwords.words('german'))
if fname is None:
fname = "./data/train.txt"
texts = []
labels = []
#split the lines into text and labels and save separately
with open(fname) as f1:
for l1 in f1:
ws,lab = l1.decode("utf-8").split("\t")
texts.append(ws)
labels.append(lab.strip())
#character embeddings
#words = word_tokenize(words_raw)
tokensents = [tk.lower().split() for tk in texts]
words = set([word for tokens in tokensents for word in tokens])
chars = list(' '.join(words))
char_counts = Counter(chars)
labels_dict = {}
labels_nr = []
nums = set()
for i1,lab in enumerate(labels):
#this step will be explained later and means, that setences with maximum of only 2 tokens should
# be ignored
if all==0 and len(tokensents[i1])<=2:
continue
nums.add(i1)
if lab in labels_dict:
labels_nr.append(labels_dict[lab])
else:
labels_dict[lab] = len(labels_dict)
labels_nr.append(labels_dict[lab])
tokensents = [tk for i1,tk in enumerate(tokensents) if i1 in nums]
return labels, labels_nr, labels_dict, tokensents, words, chars, char_counts
#training data
fname="https://scholar.harvard.edu/files/malmasi/files/vardial2018-gdi-training.zip"
target_path = download_file(fname)
extract_zip( target_path, "./data/")
labels_train, labels_nr_train, labels_dict_train,sents_train_raw, words_train, chars_train, char_counts_train = get_data()
labels_dev_dev, labels_nr_dev, labels_dict_dev,sents_dev_raw, words_dev, chars_dev, char_counts_dev = get_data("./data/dev.txt")
sents_train= [" ".join(tk).lower() for tk in sents_train_raw]
sents_dev= [" ".join(tk).lower() for tk in sents_dev_raw]Let’s try to classify it:
from sklearn.metrics import f1_score
from sklearn.svm import LinearSVC
from sklearn.feature_extraction.text import TfidfVectorizer,CountVectorizer
n_features=20000
clf_svm = LinearSVC(random_state=0,C=1)
tf_vectorizer = CountVectorizer( min_df=2,
max_features=n_features)
tf_train = tf_vectorizer.fit_transform(sents_train)
tf_dev = tf_vectorizer.transform(sents_dev)
clf_svm.fit(tf_train,labels_nr_train)
print("SVM TF weighted",f1_score(clf_svm.predict(tf_dev),labels_nr_dev, average="weighted"))
print("SVM TF macro",f1_score(clf_svm.predict(tf_dev),labels_nr_dev, average="macro"))Output:
SVM TF weighted 0.6100404138001064
SVM TF macro 0.6036412574311785This seems already pretty good, compared to last years results, where the best score was 0.66 (weighted F-1 score). So far we are 9th place. There are still 8 other different approaches left, making up for those 0.05 points of difference of our score compared to the best score, which we intend to surpass. Let’s see how.
It is all about preprocessing
But we can do much better using just a simple trick: We skip the one and two words sentences, such as “jo jo”. This is because they are bad for training the classifier. Why are they bad, mostly for two reasons: a) too few features (only one and two words), therefore difficult to differentiate especially TF or TF-IDF get somwhat confused, and b) also very confusing labels. That means the same sentence being labelled with two different labels, e.g. the “jo jo” sentence (line 15 of training data was labelled first BS and later in line 2921 LU). Let’s see how good this works.
labels_train, labels_nr_train, labels_dict_train,sents_train_raw, words_train, chars_train, char_counts_train = get_data(all=0)
labels_dev_dev, labels_nr_dev, labels_dict_dev,sents_dev_raw, words_dev, chars_dev, char_counts_dev = get_data("dev.txt.gz",all=0)
sents_train= [" ".join(tk).lower() for tk in sents_train_raw]
sents_dev= [" ".join(tk).lower() for tk in sents_dev_raw]
tf_train = tf_vectorizer.fit_transform(sents_train)
tf_dev = tf_vectorizer.transform(sents_dev)
clf_svm.fit(tf_train,labels_nr_train)
print("SVM TF weighted",f1_score(clf_svm.predict(tf_dev),labels_nr_dev, average="weighted"))
print("SVM TF macro",f1_score(clf_svm.predict(tf_dev),labels_nr_dev, average="macro"))Output:
SVM TF weighted 0.6438060442167858
SVM TF macro 0.6366767077208305Wow, 3 additional points, which gives us already fourth place compared to last year. Surprisingly, we are just counting the words appearing in the sentences. Normally, SVMs work best with normalized data, but let’s leave that for another tutorial.
Let’s see if there is a weighting scheme better than term frequency. Normally Term-Frequency Inverse-Document-Frequency (TF-IDF) works better for document classification.
tfidf_vectorizer = TfidfVectorizer( min_df=2,
norm="l2",
max_features=n_features)
tfidf_train = tfidf_vectorizer.fit_transform(sents_train)
tfidf_dev = tfidf_vectorizer.transform(sents_dev)
clf_svm.fit(tfidf_train,labels_nr_train)
print("SVM TF-IDF weighted",f1_score(clf_svm.predict(tfidf_dev),labels_nr_dev, average="weighted"))
print("SVM TF-IDF macro",f1_score(clf_svm.predict(tfidf_dev),labels_nr_dev, average="macro"))Output:
SVM TF-IDF weighted 0.659225631519502
SVM TF-IDF macro 0.6514922794527852This would give us third place, almost second. But this is with SVM – do others classifiers perform well?
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import BaggingClassifier
import numpy as np
import scipy.sparse
clf = RandomForestClassifier(max_depth=5, n_estimators=1000, random_state=0)
clf.fit(tf_train,labels_nr_train)
print("RF TF weighted",f1_score(clf.predict(tf_dev),labels_nr_dev, average="weighted"))
print("RF TF macro",f1_score(clf.predict(tf_dev),labels_nr_dev, average="macro"))
clf.fit(tfidf_train,labels_nr_train)
print("RF TF-IDF weighted",f1_score(clf.predict(tfidf_dev),labels_nr_dev, average="weighted"))
print("RF TF-IDF macro",f1_score(clf.predict(tfidf_dev),labels_nr_dev, average="macro"))
bagging = BaggingClassifier( RandomForestClassifier(max_depth=5, n_estimators=1000, random_state=0),
max_samples=0.5, max_features=0.5)
bagging.fit(tf_train,labels_nr_train)
print("Bagging TF weighted",f1_score(bagging.predict(tf_dev),labels_nr_dev, average="weighted"))
print("Bagging TF macro",f1_score(bagging.predict(tf_dev),labels_nr_dev, average="macro"))
from sklearn.ensemble import BaggingClassifier
bagging = BaggingClassifier( RandomForestClassifier(max_depth=5, n_estimators=1000, random_state=0),
max_samples=0.5, max_features=0.5)
bagging.fit(tfidf_train,labels_nr_train)
print("Bagging TFIDF weighted",f1_score(bagging.predict(tfidf_dev),labels_nr_dev, average="weighted"))
print("Bagging TFIDF macro",f1_score(bagging.predict(tfidf_dev),labels_nr_dev, average="macro"))
bagging = BaggingClassifier( RandomForestClassifier(max_depth=5, n_estimators=1000, random_state=0),
max_samples=0.5, max_features=0.5)
bagging.fit(scipy.sparse.hstack([tf_train,tfidf_train]).tocsr(),labels_nr_train)
print("Bagging TF+TFIDF weighted",f1_score(bagging.predict(scipy.sparse.hstack([tf_dev,tfidf_dev]).tocsr()),labels_nr_dev, average="weighted"))
print("Bagging TF+TFIDF macro",f1_score(bagging.predict(scipy.sparse.hstack([tf_dev,tfidf_dev]).tocsr()),labels_nr_dev, average="macro"))Output:
RF TF weighted 0.4885197964113094
RF TF macro 0.4221673549708851
RF TF-IDF weighted 0.4893916483789577
RF TF-IDF macro 0.4228223976071996
Bagging TF weighted 0.4789533772991431
Bagging TF macro 0.39480401932741443
Bagging TFIDF weighted 0.47137943835930063
Bagging TFIDF macro 0.3838371628473811
Bagging TF+TFIDF weighted 0.45362385515145237
Bagging TF+TFIDF macro 0.3778279814338985
Bagging and Random Forest (RF) sometimes are good, sometimes are bad; in this case applying bagging decreases the SVMs’ performance.
Let’s stick with SVM for now. We will now try to use character-based n-ngrams, since our task, differentiating between the dialects, is mostly about spelling, which can be indirectly perceived by the histogram of characters.
tf_vectorizer_char_ngram = CountVectorizer( min_df=2,
analyzer="char",
max_features=n_features, ngram_range=(1, 7))
tf_train_char_ngram = tf_vectorizer_char_ngram.fit_transform(sents_train)
tf_dev_char_ngram = tf_vectorizer_char_ngram.transform(sents_dev)
clf_svm.fit(tf_train_char_ngram,labels_nr_train)
preds=clf_svm.predict(tf_dev_char_ngram)
print("SVM TF-IDF tf char ngram 7",f1_score(preds,labels_nr_dev, average="weighted"))
print("SVM TF-IDF tf char ngram macro",f1_score(preds,labels_nr_dev, average="macro"))
Output:
SVM TF-IDF tf char ngram weighted 0.6558271945540242
SVM TF-IDF tf char ngram macro 0.6468589036370523Not bad, counting characters is about as good as TF-IDF with words. What about TF-IDF of characters?
# additionally use normlized tfidf char bigrams
tfidf_vectorizer_char_ngram = TfidfVectorizer( min_df=2,
norm="l2",
analyzer="char",
max_features=n_features, ngram_range=(1, 7))
tfidf_train_char_ngram = tfidf_vectorizer_char_ngram.fit_transform(sents_train)
tfidf_dev_char_ngram = tfidf_vectorizer_char_ngram.transform(sents_dev)
clf_svm.fit(tfidf_train_char_ngram,labels_nr_train)
preds=clf_svm.predict(tfidf_dev_char_ngram)
print("SVM TF-IDF tf char ngram 7",f1_score(preds,labels_nr_dev, average="weighted"))
print("SVM TF-IDF tf char ngram macro",f1_score(preds,labels_nr_dev, average="macro"))Output:
SVM TF-IDF tf char ngram weighted 0.6774906696759666
SVM TF-IDF tf char ngram macro 0.6658621351916394Wow, now we would win the competition from 2017! Here we also see that TF-IDF works well for sentences and characters. But this was out of the box, can we create better bi-grams? And why bi-grams? Because we are looking for features which are phonetically similar and similarly structured, allowing not quite perfect match. Also it gives us a kind of histogram over the phonemes. Furthermore, the number of “aas” and “ee” might give good hints. We’ll show you why the tfidf_vectorizer with char n-gram could do even better:
tfidf_vectorizer_char_ngram.get_feature_names()[:20]Output:
[' ',
' a',
' a ',
' a d',
' a d ',
' a de',
' a de ',
' aa',
' aa ',
' aab',
' aabe',
' aaf',
' aafa',
' aafan',
' aafang',
' aag',
' aagf',
' aagfa',
' aagfan',
' aagl']We can see lots of white spaces, which do not provide a good insight on the structure of the words. However, silence is an important part of the music, so we will try without it, that means removing the spaces. Also until now we examined with only one feature, the winner of last year’s competition did win with multiple features. Can we mix them somehow and get better results?
def gather_bigrams(data):
res = set()
for n1 in data:
res.update(bigrams(n1))
return list(res)
def bigrams(word):
chars = [c for c in word]
bigrams = [c1 + c2 for c1, c2 in zip(chars, chars[1:])]
features = chars + bigrams
return features
def transform_features(data_train, data_test, n_grams=1):
bigrams_list = gather_bigrams([tj for tk in data_train for tj in tk.split() if tj.find(" ")==-1])
cv = CountVectorizer(
analyzer=bigrams,
# analyzer="char",
preprocessor=lambda x : x,
vocabulary=bigrams_list,
ngram_range=(1, n_grams))
X_train = cv.fit_transform(data_train)
X_test = cv.transform(data_test)
return X_train, X_test
X_train, X_test = transform_features(sents_train,sents_dev)
clf_svm.fit(X_train,labels_nr_train)
preds=clf_svm.predict(X_test)
print("SVM CV + Bigrams weighted",f1_score(preds,labels_nr_dev, average="weighted"))
print("SVM CV + Bigrams macro",f1_score(preds,labels_nr_dev, average="macro"))
clf_svm.fit(scipy.sparse.hstack([tfidf_train,X_train]),labels_nr_train)
preds=clf_svm.predict(scipy.sparse.hstack([tfidf_dev.todense(),X_test]))
print("SVM CV + Bigrams weighted TF-IDF+Bigrams",f1_score(preds,labels_nr_dev, average="weighted"))
print("SVM CV + Bigrams macro TF-IDF+Bigrams",f1_score(preds,labels_nr_dev, average="macro"))Output:
SVM CV + Bigrams weighted 0.5910983725307404
SVM CV + Bigrams macro 0.5789372643322429
SVM CV + Bigrams weighted TF-IDF+Bigrams 0.6773374236772861
SVM CV + Bigrams macro TF-IDF+Bigrams 0.6700263168459002Although by itself, this simple bi-gram analyzer performs poorly, in combination with TF-IDF, it increased the macro F-1 score considerably. The 0.005 increase compared to TF-IDF alone is what makes the biggest difference between the final scores. So, combining single features might be a good approach.
Merging Features
Let’s try to answer the following question: What is the impact of using n-grams instead of words for TF-IDF (while keeping the character bi-grams)?
tfidf_vectorizer_ngram = TfidfVectorizer( min_df=2,
norm="l2",
max_features=n_features, ngram_range=(1, 7))
tfidf_train_ngram = tfidf_vectorizer_ngram.fit_transform(sents_train)
tfidf_dev_ngram = tfidf_vectorizer_ngram.transform(sents_dev)
clf_svm.fit(scipy.sparse.hstack([tfidf_train_ngram,X_train]),labels_nr_train)
preds=clf_svm.predict(scipy.sparse.hstack([tfidf_dev_ngram,X_test]))
print("SVM TF-IDF + Bigrams + word 7 ngram 5",f1_score(preds,labels_nr_dev, average="weighted"))
print("SVM TF-IDF + Bigrams + word 7 ngram macro",f1_score(preds,labels_nr_dev, average="macro"))Output:
SVM TF-IDF + Bigrams + word 7 ngram weighted 0.678517820542825
SVM TF-IDF + Bigrams + word 7 ngram macro 0.6686880145927554Apparently lower macro and higher weighted F-1 score. What about using custom bi-grams?
X_train_ngrams, X_test_ngrams = transform_features(sents_train,sents_dev, n_grams=7)
clf_svm.fit(scipy.sparse.hstack([tfidf_train_ngram,X_train_ngrams]),labels_nr_train)
preds=clf_svm.predict(scipy.sparse.hstack([tfidf_dev_ngram,X_test_ngrams]))
print("SVM TF-IDF + Bigrams + char 7 ngram 6",f1_score(preds,labels_nr_dev, average="weighted"))
print("SVM TF-IDF + Bigrams + char 7 ngram macro",f1_score(preds,labels_nr_dev, average="macro"))
Output:
SVM TF-IDF + Bigrams + char 7 ngram weighted 0.678517820542825
SVM TF-IDF + Bigrams + char 7 ngram macro 0.6686880145927554It looks like no changes, likely because the n-grams are already covering whitespace problems. Let’s try to put even more features together.
clf_svm.fit(scipy.sparse.hstack([tfidf_train_ngram,X_train_ngrams,tfidf_train_char_ngram]),labels_nr_train)
preds=clf_svm.predict(scipy.sparse.hstack([tfidf_dev_ngram,X_test_ngrams,tfidf_dev_char_ngram]))
print("SVM TF-IDF + Bigrams + char 7 ngram (bigrams) tfidf chars ngrams + tf char ngram 7",f1_score(preds,labels_nr_dev, average="weighted"))
print("SVM TF-IDF + Bigrams + char 7 ngram (bigrams) tfidf chars ngrams + tf char ngram macro",f1_score(preds,labels_nr_dev, average="macro"))Output:
SVM TF-IDF + Bigrams + char 7 ngram (bigrams) tfidf chars ngrams + tf char ngram weighted 0.6807815919337346
SVM TF-IDF + Bigrams + char 7 ngram (bigrams) tfidf chars ngrams + tf char ngram macro 0.6708978004436262Nice, slightly more for both scores. Now, lets try normalizing the tf and using character n-gram count.
from sklearn.preprocessing import normalize
tf_vectorizer_char_ngram = CountVectorizer( min_df=2,
analyzer="char",
max_features=n_features, ngram_range=(1, 7))
tf_train_char_ngram = tf_vectorizer_char_ngram.fit_transform(sents_train)
tf_dev_char_ngram = tf_vectorizer_char_ngram.transform(sents_dev)
tf_train_char_ngram = normalize(tf_train_char_ngram)
tf_dev_char_ngram = normalize(tf_dev_char_ngram)
clf_svm.fit(scipy.sparse.hstack([tfidf_train_ngram,X_train_ngrams,tfidf_train_char_ngram,tf_train_char_ngram]),labels_nr_train)
preds=clf_svm.predict(scipy.sparse.hstack([tfidf_dev_ngram,X_test_ngrams,tfidf_dev_char_ngram,tf_dev_char_ngram]))
print("SVM TF-IDF + Bigrams + char 7 ngram (bigrams) tfidf chars ngrams + tf char ngram 8",f1_score(preds,labels_nr_dev, average="weighted"))
print("SVM TF-IDF + Bigrams + char 7 ngram (bigrams) tfidf chars ngrams + tf char ngram macro",f1_score(preds,labels_nr_dev, average="macro"))Output:
SVM TF-IDF + Bigrams + char 7 ngram (bigrams) tfidf chars ngrams + tf char ngram weighted 0.6817307419317699
SVM TF-IDF + Bigrams + char 7 ngram (bigrams) tfidf chars ngrams + tf char ngram macro 0.6725325917465754Ok, not much difference, but still an increase.
Merging Predictions
Until now we just concatenated the features, but they are quite different, and can cause the SVMs to give more importance to features with higher value. A possible counter action would be to normalize it. Yet, since we have many different features and many different possible ways to normalize (over train, over feature, over sample, linear versus non-linear), we will use separate SVMs and use voting (ensemble voting).
svms=[]
for tk in [tfidf_train_ngram,X_train_ngrams,tfidf_train_char_ngram,tf_train_char_ngram]:
svms.append(LinearSVC(random_state=0, C=1))
svms[-1].fit(tk,labels_nr_train)
svms_preds=[]
for i1,tk in enumerate([tfidf_dev_ngram,X_test_ngrams,tfidf_dev_char_ngram,tf_dev_char_ngram]):
svms_preds.append(svms[i1].predict(tk))
sumpres=[Counter(np.array(svms_preds)[:,tk]).most_common()[0][0] for tk in range(len(svms_preds[0]))]
print("SVM TF-IDF separate svm for features Bigrams char 7 ngram 9",f1_score(sumpres,labels_nr_dev, average="weighted"))
print("SVM TF-IDF separate svm for features Bigrams char 7 ngram macro",f1_score(sumpres,labels_nr_dev, average="macro"))
Output:
SVM TF-IDF separate svm for features Bigrams char 7 ngram weighted 0.6894441553644064
SVM TF-IDF separate svm for features Bigrams char 7 ngram macro 0.6758401343396775
Cool, not bad, almost one point in weighted F-1. But again, the vote is not weighted, we are giving the same importance for each feature SVM, handling low and high score predictions equally. What if we use the scores of the SVM (decision_function) for the weighting?
svms=[]
for tk in [tf_train, tfidf_train, tfidf_train_ngram,X_train_ngrams,tfidf_train_char_ngram,tf_train_char_ngram]:
svms.append(LinearSVC(random_state=0, C=1))
svms[-1].fit(tk,labels_nr_train)
svms_preds=[]
for i1,tk in enumerate([tf_dev, tfidf_dev,tfidf_dev_ngram,X_test_ngrams,tfidf_dev_char_ngram,tf_dev_char_ngram]):
svms_preds.append(svms[i1].decision_function(tk))
sumpres=sum([tk for tk in svms_preds])
print("SVM TF-IDF separate svm for features Bigrams char 7 ngram 10",f1_score(np.argmax(sumpres,1),labels_nr_dev, average="weighted"))
print("SVM TF-IDF separate svm for features Bigrams char 7 ngram macro",f1_score(np.argmax(sumpres,1),labels_nr_dev, average="macro"))
Output:
SVM TF-IDF separate svm for features Bigrams char 7 ngram weighted 0.6970817681702751
SVM TF-IDF separate svm for features Bigrams char 7 ngram macro 0.687829000954753
Much better, almost 0.70. We would have easily beaten the winner of last year’s competition.
Still, the sum seems poor… can we build a meta classifier?
Meta-Classifier
A meta classifier could learn between the SVMs. Also most importantly, each SVM could specialize in the feature space, so any type of normalization could be avoided.
svms=[]
for tk in [tfidf_train_ngram,X_train_ngrams,tfidf_train_char_ngram,tf_train_char_ngram]:
svms.append(LinearSVC(random_state=0, C=1))
svms[-1].fit(tk,labels_nr_train)
svms_train_meta=[]
for i1,tk in enumerate([tfidf_train_ngram,X_train_ngrams,tfidf_train_char_ngram,tf_train_char_ngram]):
svms_train_meta.append(svms[i1].decision_function(tk))
svm_meta=LinearSVC(random_state=0, C=0.75)
svm_meta.fit(scipy.sparse.hstack([np.concatenate(svms_train_meta,1),tfidf_train_ngram,X_train_ngrams,tfidf_train_char_ngram,tf_train_char_ngram]),labels_nr_train)
svms_preds=[]
for i1,tk in enumerate([tfidf_dev_ngram,X_test_ngrams,tfidf_dev_char_ngram,tf_dev_char_ngram]):
svms_preds.append(svms[i1].decision_function(tk))
svm_meta_preds=svm_meta.decision_function(scipy.sparse.hstack([np.concatenate(svms_preds,1),tfidf_dev_ngram,X_test_ngrams,tfidf_dev_char_ngram,tf_dev_char_ngram]))
print("Meta SVM TF-IDF separate svm for features Bigrams char 7 ngram",f1_score(np.argmax(svm_meta_preds,1),labels_nr_dev, average="macro"))Output:
Meta SVM TF-IDF separate svm for features Bigrams char 7 ngram macro 0.6678147793590107That was not good, probably the classifiers did too well in the training set. The solution is to do a cross validation, i.e. slice the training data e.g. in 5 slices, use one slice for testing and the others for training, and iterate, switching the test slice every time (5 times in total). We make predictions on the test slice; gathering all predictions creates a prediction set with which we can train a meta classifier.
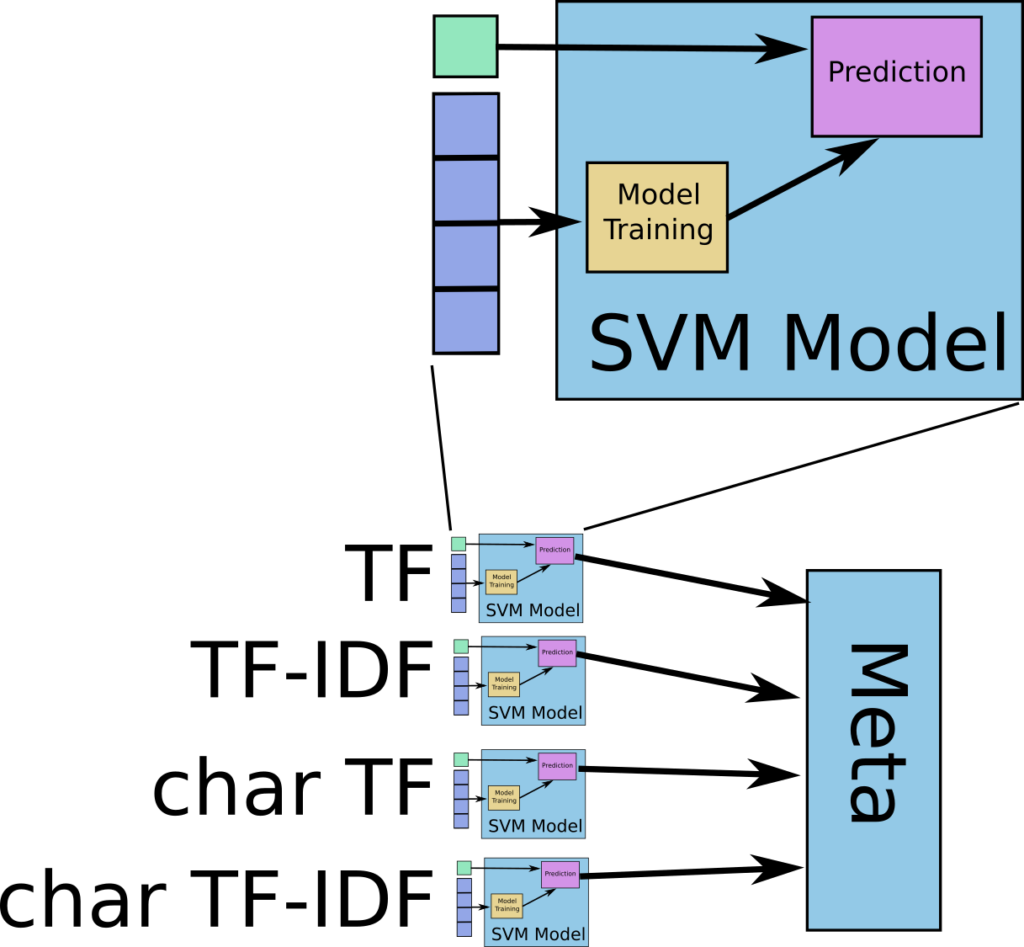
We did not refactor the code, so it can be quite long to go through, but we hope you see what the main idea is. We use the helper function perform (described further below) from meta_cv (we will go into this with more detail in another blog post). Let’s see the results:
import meta_cv
meta_cv.perform(0)Output:
uall 0 comp 0 tf 0
Meta weighted 0.7010140759532392
Meta macro 0.6906810078254101Nice, now we are set to compete (apply to real test set).
meta_cv.perform(1)Output:
uall 0 comp 1 tf 0
Meta weighted 0.6541038424460858
Meta macro 0.6463870277698942
Ok, with that result we got second place, without any parameter tuning. We will discuss in the next blog post, how we can analyze our results and improve our parameters.
Below is the perform helper function:
from meta_cv import MetaCV
#download gold labels
gold_dir=“./data/gold/”
if not os.path.exists(gold_dir):
os.makedirs(gold_dir)
target_path_gold=download_file(“https://drive.google.com/uc?authuser=0&id=0B8I6bgWbt_MfWHJrNDhpOFVVcUhabGFxWDJUWG9LR2hGODFJ&export=download”, target_path=gold_dir+“testdata_fixed.zip”)
extract_zip( target_path_gold, gold_dir)
def perform(comp):
meta=MetaCV(splits=5)
print ("comp",comp)
labels_train, labels_nr_train, labels_dict_train,sents_train_raw, words_train, chars_train, char_counts_train = get_data(all=0)
labels_dev_dev, labels_nr_dev, labels_dict_dev,sents_dev_raw, words_dev, chars_dev, char_counts_dev = get_data(fname=os.path.join(os.path.dirname(os.path.realpath(__file__)),"./data/dev.txt", all=0))
sents_train= [" ".join(tk).lower() for tk in sents_train_raw]
sents_dev= [" ".join(tk).lower() for tk in sents_dev_raw]
labels_dev_dev, labels_nr_dev, labels_dict_dev,sents_dev_raw, words_dev, chars_dev, char_counts_dev = get_data(fname=os.path.join(os.path.dirname(os.path.realpath(__file__)),"./data/dev.txt",all=0))
labels_test, labels_nr_test, labels_dict_test,sents_test_raw, words_test, chars_test, char_counts_test = preprocessing.get_data(fname=os.path.join(os.path.dirname(os.path.realpath(__file__)),"./data/gold/gold.txt"))
if comp==0:
meta.fit(sents_train,labels_nr_train)
preds=meta.predict(sents_dev)
print("SVM TF",f1_score(preds,labels_nr_dev, average="weighted"))
print("SVM TF macro",f1_score(preds,labels_nr_dev, average="macro"))
else:
rev_labels_dict_train = dict([(tv,tk) for tk,tv in labels_dict_train.items()])
sents_train_comp= [" ".join(tk).lower() for tj in [sents_train_raw,sents_dev_raw] for tk in tj]
labels_nr_train_comp = [ tk for tj in [labels_nr_train,labels_nr_dev] for tk in tj]
meta.fit(sents_train_comp,labels_nr_train_comp)
sents_test_comp= [" ".join(tk).lower() for tk in sents_test_raw]
preds=meta.predict(sents_test_comp)
labels_preds=[rev_labels_dict_train[np.argmax(tk)] for tk in preds]
with open("prediction.labels","w") as f1:
for label in labels_preds:
f1.write(label+"\n")
from sklearn.model_selection import cross_val_score
preds_score=meta.decision_function(sents_test_comp)
trf=np.argmax(preds_score,1)
rev_labels_dict_train=dict([(tv,tk) for tk,tv in labels_dict_train.items()])
rev_labels_dict_train[-1]="XY"
tr_labs=[rev_labels_dict_train[trf[tk]] for tk in range(trf.shape[0])]
with open("predictions_c5_metacv_multiclass_threshold.labels","w") as f1:
for tr1 in tr_labs:
f1.write(tr1+"\n")
gdi4=np.isin(labels_nr_test,[labels_dict_test[tk] for tk in ["ZH","LU","BE","BS"]])
index=np.where(gdi4)[0]
print("SVM TF",f1_score([labels_dict_test[rev_labels_dict_train[tk]] for tk in np.array(trf)[index]],np.array(labels_nr_test)[index], average="weighted"))
print("SVM TF macro",f1_score([labels_dict_test[rev_labels_dict_train[tk]] for tk in np.array(trf)[index]],np.array(labels_nr_test)[index], average="macro"))
return index, gdi4,trf, labels_dict_test,rev_labels_dict_train,labels_nr_test, preds_score